
Machine deep learning is one of the major breakthroughs in the field of artificial intelligence in recent years. It has achieved many successes in the fields of speech recognition, natural language processing, and computer vision. And what are the breakthrough applications for deep learning for the current hot driverless?
Due to the complex driving environment of vehicles, current sensing technology cannot meet the development needs of unmanned driving in terms of detection and recognition accuracy. Deep learning has proved to have great advantages in complex environment perception.
Recently, in response to this topic, Yu Guizhen, an associate professor at the School of Transportation, Beijing University of Aeronautics and Astronautics, shared his experience and experience in the application of deep learning in the perception of unmanned driving environment during the 2016 China Automotive Engineering Society and Exhibition. . Yu Guizhen's research direction is mainly the perception and control of intelligent transportation and driverless driving.
Visual perception is the core technology of driverlessness
Unmanned driving generally consists of four levels or five levels, regardless of which level includes three aspects: environmental awareness, planning decision and execution control. Among them, the environment perception methods mainly include visual perception, millimeter wave radar sensing and laser radar sensing. Among them, visual perception is the most important way of unmanned driving.
Recently, the Tesla incident has been heated up. One is in the United States and the other is in China. I want to talk about it from a technical point of view.
In the US incident, the millimeter-wave radar on the Tesla was unable to detect the truck's high compartment because of the low installation position. The camera should be able to detect the truck. We know that the Tesla vehicle is from far to near. So from this point of view it is generally possible to detect the truck. But when it finally got together, there might be problems, and no trucks were detected.
In the accidents in China, due to the sudden change of the preceding vehicle, the faulty vehicles are close to Tesla, and they are in the blind area of ​​visual perception and radar. The millimeter-wave radar cannot scan the close-range sidecars due to the problem of the front angle. In addition, since the part of the faulty vehicle appears in the camera, there is no way to detect the visual perception, and a scraping accident of Tesla occurs.
Therefore, it can be seen from the above accidents that visual perception still needs to be improved.
The road conditions in China are more complicated, rainy days, foggy days and snowy days. In addition, phenomena such as carriages, cranes and motorcycles, as well as motorcycles pulling pigs and trucks, are often encountered in our lives. These scenes are a problem for vision. Improving the perception accuracy under such complex road conditions is unmanned. The challenge of driving research.
Deep learning can meet the high precision requirements of visual perception in complex road conditions
Deep learning is considered to be an effective solution. Deep learning is a simulation of the human brain. It has been a major breakthrough in artificial intelligence in the past 10 years. Deep learning should have made great progress in visual perception in recent years. Compared with traditional computer vision, deep learning has great advantages in visual perception accuracy.
Especially after 2011, it has been reported that if the algorithm and sample size are sufficient for deep learning, the accuracy rate can reach over 99.9%, and the limit of traditional visual algorithm detection accuracy is about 93%. The perception of human beings, that is, the accuracy that people can see is generally 95%, so from this perspective, deep learning has an advantage in visual perception.
The so-called deep learning, also known as deep neural network, is a neural network machine learning algorithm with more layers and nodes than the previous neural network. From this, it can be seen that deep learning is a kind of machine learning. It is a smarter machine learning. The main types of deep learning generally include five types, such as CNN, RNN, LSTM, RBM and Autoencoder. Among them, we mainly use CNN, and CNN has another name called convolutional neural network. Convolutional neural networks have proven to be very effective in image processing.
Among them, the self-learning feature is the biggest advantage of deep learning. For example, smart driving needs to identify a dog. In the previous algorithm, if a dog is to be identified, the characteristics of the dog should be described in detail by using a program. If a sufficient sample is collected in the deep learning area, then it is trained in deep learning and trained. The system can recognize this dog. Traditional computer vision algorithms need to extract features manually. Many times, expert knowledge is needed. The robust design of the algorithm is very difficult. It is difficult to guarantee robustness. We encounter many difficulties when we do visual perception. In addition, if you want to ensure this stability requires a lot of debugging, it is very time consuming.
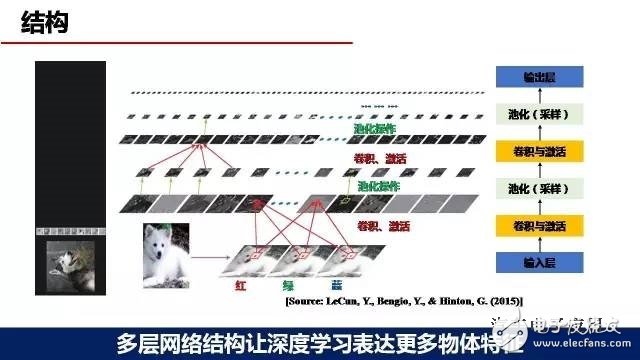
Deep learning generally includes four types of neural network layers, an input layer, a convolution layer, a pooling layer, and an output layer. The structure of the network can be 10 layers or even hundreds of layers. The more the number of layers, the more accurate the detection accuracy will be. And as the number of network layers and the number of nodes increase, more fine and more features of the identifier can be expressed, which can lay a foundation for improving the detection accuracy.
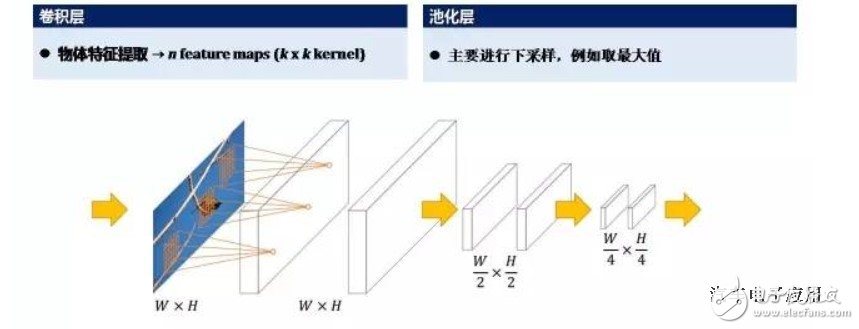
The convolutional layer and the pooled layer are the core processing layers of deep learning. The convolution layer is mainly used to be responsible for the extraction of object features; the pooling layer is mainly responsible for sampling. For example, a simple understanding of the pooling layer, (that is, a maximum value in a Sudoku), this is the pooling layer. The convolutional layer and the pooled layer are the layers of the two cores of deep learning.
The principle of deep learning, deep learning generally includes two aspects, one is training, one is testing, training is generally mainly offline, that is, the collected samples are input into the training network. The training network performs forward output, then uses the calibration information for feedback, and finally trains the model. This model is imported into the detected network, and the detection network can detect and identify the input video and image. In general, the more the number of samples, the higher the accuracy of recognition, so the number of samples is an important factor affecting the accuracy of deep learning.
Deep learning has broad application prospects in driverless perception
The depth of learning used in general environmental perception will be more, mainly in the field of vision and millimeter wave radar. Machine learning is also used in driving strategies, but we are generally called reinforcement learning, which is used in driving strategy research. In terms of environmental perception, deep learning can be advantageous in terms of visual perception, lidar sensing, and driver condition monitoring, even in the fusion of camera and millimeter wave radar.
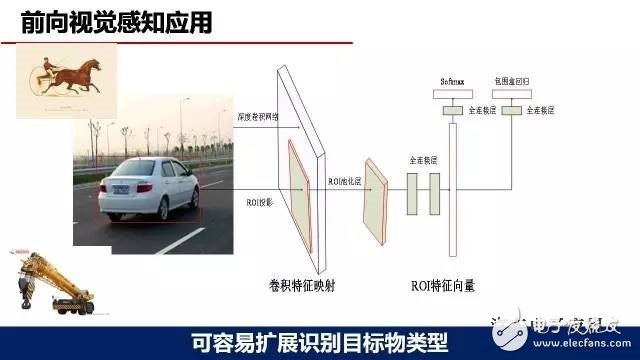
In terms of context awareness, the important work we do in this area is the forward visual perception application. Everyone knows that forward visual perception is an important part of driverlessness, and we try to learn some applications in this area. The main use of the monocular camera solution, the selected model is Faster R-CNN, running on the GPU TITAN platform. Target detection products mainly include lane lines, vehicles, pedestrians, traffic signs and bicycles. At present, there are about 30,000 samples of vehicles, about 20,000 pedestrian samples, and other samples are less, about 1000-2000. From the perspective of operational effects, we believe that there are significant improvements in recognition accuracy and recognition types compared to some traditional visual algorithms developed in the past.
One of the advantages of deep learning is that it is easy to extend the target object type.
The second advantage of deep learning can improve the recognition accuracy of partially occluded objects.

For example, in Fig. 1, if a conventional visual algorithm is employed, it is difficult for a general vehicle to detect in front of the vehicle. In Fig. 2, the detection result of the deep learning can be seen. The front of the red car has been manned and the bicycle, but the vehicle can still be detected, and the deep learning can improve the recognition accuracy of the partially occluded object.
The third advantage of deep learning can solve the problem of difficult identification in the video of the vehicle in the front lane.

Figure 1 shows the traditional algorithm, the white vehicle in the right lane is not detected. Why is it not detected? We know that the general traditional algorithm is mainly to detect the car at the rear of the vehicle. The lateral detection of the vehicle is not good. The approaching vehicle near your nearest two lanes is actually a dangerous thing for you. If I can detect some vehicles in the left and right vehicles, I think this is a big improvement to the vision. The Tesla accident mentioned earlier means that a car parked on the roadside, and the car in front of it suddenly turned. The accident was caused by the fact that the vehicle was too close to it and did not detect the faulty vehicle. From Figure 2 we can see the effect of our deep learning detection. The vehicle in the right lane is only partially in the image and the vehicle can still be detected. Therefore, we feel that the use of deep learning can solve the problem that the part of the vehicle is difficult to identify in the video.
The fourth advantage of deep learning can reduce the impact of light changes on the accuracy of object recognition.
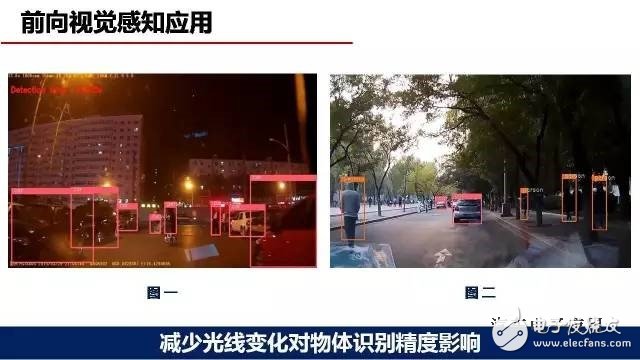
Figure 1 shows the recognition effect at night, but in fact there are no vehicles and pedestrians in the evening in our entire training sample. In the end, we took the network after training and tested the video at night. The effect was good. As you can see in Figure 2, a few people under the shade of the right side can actually detect a few pedestrians if they are difficult to see with the naked eye, but using deep learning can basically detect pedestrians. The above is some of our experiences in deep learning, not necessarily correct, because we just did some rough research. More detailed questions, if you have any good suggestions, or find something new, we can share them together.
summary:
1, deep learning in the aspect of unmanned visual perception, compared to traditional visual algorithms, has certain advantages in accuracy, environmental adaptability and scalability. The few that I saw earlier are summaries of some of the practices we have done.
2, deep learning We know that in addition to visual aspects, in millimeter wave radar, laser radar and even driver identification, we feel that there are also broad application prospects. In particular, the driver status recognition, I would like to mention, because some of Tesla's recent events are the driver's unmanned state, then the handle is spread out the steering wheel, the hand is not on the steering wheel. If we have a camera that can detect the driver's status, then the driver can be alerted, even if the driver is on the steering wheel, which can reduce the accident.
3, our PPT is only to explore some of the shallow application of deep learning in video detection, there are still many technical difficulties to overcome from engineering applications.
EvoTec Special Generator including Low Power Generator,Ip55 Generator,Synchronous Brushless Alternator For Diesel,Diesel Synchronous Brushless Alternator.Our alternator are widely used in industry, commercial, real estate, hospital, hotel, railway, telecommunications, data-centers and mining etc.
The specific technical features are listed below:
Speed: 1500rpm or 1800rpm
Frequency: 50 Hz or 60Hz
Number of Poles: 4
Power: up to 3500KVA
Voltage: 110V-690V,High Voltage:3.3KV-13.8KV
Insulation: class H
Power Factor: 0.8
Voltage Regulation Rate: ±0.5%
Altitude: 1000M
Temperature Rise Class: class H
Ambient Temperature: 40
Overload:10% for 1 hour in every 12 hours
Degree of Protection: IP21 (IP23, IP44, IP54 on request)
Special Features:
- higher motor starting capability
- a reliable long life with superior class H insulation
- high thyristor load withstand capability for mobile phone and telecom applications
- ease of maintenance with integrated components and outboard exciter/rotating rectifier
- wide range of coupling discs/adaptor for single bearing configuration, suitable for wide range of engine brand
IP55 Generator

Low Power Generator,Ip55 Generator,Synchronous Brushless Alternator For Diesel,Diesel Synchronous Brushless Alternator
EvoTec Power Generation Co., Ltd , https://www.evotecgen.com