Lei Feng network press: author of this article phunter, article source big data talk. The article only describes how to use MXnet to make artistic style photos.
Neural art: imitating van Gogh with a machine
Neural art is an algorithm that allows a machine to repaint a picture by mimicking the painting style of an existing painting. For example, a picture of a cat and a self portrait of Van Gogh, we can get a cat painted in Van Gog style. This is what it looks like (Figure 2 shows Van Gogh's self-portrait in 1889, quoted from wikipedia):

The Neural art algorithm comes from this paper "A Neural Algorithm of Artistic Style" by Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge, who are interested in visiting the friends at http://arxiv.org/abs/1508.06576 Can read.
Its basic idea is to use a multi-layered convolutional network (CNN) to abstract out some of the advanced hidden features in a given painting to mimic the painting style and apply the painting style to a new picture. This kind of image generation model is a direction of deep learning. For example, Google's Inception generates a sheep-shaped cloud, such as a sheep-like image and a cloud image. This is a similar model. Facebook also has a similar generative model based on this http://arxiv.org/abs/1406.2661 article by DMLC author @antinucleon and others.
The Neural Art algorithm model has multiple implementations. For example, here and here are the two Lua/Torch implementations. The gitxiv of this paper also contains a variety of different implementations. They all implement the VGG model in the paper and use caffe. Description, the following example is implemented using MXnet.
MXnet's Neural Art SampleThe MXnet's neural art example is in the mxnet/example/neural-style/ directory. Because this example requires a lot of calculations, it is recommended to install the GPU version of mxnet. For a tutorial on installing the mxnet GPU version, see the previous one http://phunter.farbox.com/post/mxnet-tutorial1 This is not repeated here. Of course, mxnet's CPU and GPU are seamlessly connected. If no GPU can use the CPU version, they just need to wait about 40-50 minutes per picture.
Choose to install : mxnet optionally uses cuDNN acceleration. For the example of Neural Art, cuDNN v3 and v4 are both running, and v4 is slightly faster about 2-3 seconds than v3 on my GTX 960. You can simply perform these steps:
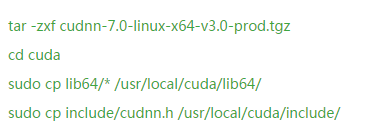
If you did not compile and install the cuDNN version of mxnet before, change the USE_CUDNN = 0 to 1 in make/config.mk to recompile and update the corresponding python package.
If you don't have the mxnet GPU version installed, you can also visit the following sites or apps to play Neural art. This algorithm requires a lot of GPU computing. The following free or paid implementations all need to be queued.
Deepart : Website https://deepart.io/ Users can submit for free. The average waiting time is about 1 week. If you want to jump into the team within 24 hours, you can donate to the website.
Pikazo App : Website http:// It's equivalent to making the deepart site an app. It costs .99 and it also needs to be queued.
AI Painter : URL https:// This is a business for instapainting, free of charge, and also needs to be queued.
If viewers and friends have exactly one machine equipped with a GPU version of mxnet, then we can begin to use mxnet to create a microblogging avatar with friends. In the following example, I used the photos of my sister @dudulee's Lang Lijia's beautiful cat “Broken Dog†as an example to explain the steps to produce the art map.
Brief steps and parameter adjustmentsMxnet uses the VGG model described in the paper. When it is used for the first time, you need to download.sh to download the model. The model version of mxnet occupies about tens of MB of space. After downloading the model, you can place the original picture you want to paint and the imitation picture in the input directory, such as broken dog photos and Van Gogh's images, and then execute:

Wait patiently for 1-2 minutes and you can see the results saved in the output directory. For example:

If you give another modern art oil painting 'Blue Horse' Modern Equine Art Contemporary Horse Daily Oil Painting by Texas Artist Laurie Pace (link https://) instead of van Gogh's paintings to let machine learning style, broken dogs can be painted like this:


There are some parameters that can be adjusted in run.py. If you want to debug the output, you can adjust it as follows:
--model Specifies the model. In the example, there is only a vgg model for the time being, and other models such as inception mentioned above may be added later. Do not change it first.
--content-image content image, such as the "breaking dog" photo above
--style-image The path of the original painting input, such as the "Van Gogh self-portrait" above.
--stop-eps In the model, eps values ​​are used to represent the style similarity of the two graphs. During the training process, this value will gradually converge. The smaller the value, the higher the similarity. The stop-eps parameter specifies the final value of the convergence. Generally, the smaller the value, the more the image is represented. However, if it is too small, it will require a lot of calculation time to converge. By default, 0.005 can have good results and can be appropriately reduced to 0.004 and so on.
--content-weight --style-weight The relative weight of the content image and the original painting. The default is 10:1. If you find that the painting style is too strongly smeared, you can modify it to 20:1 or 30:1, otherwise it will be smaller. .
--max-num-epochs The maximum number of convergence steps. The default is 1000 steps. However, the general painting can find approximately the same EPS style similarity value around 200 steps, and this maximum convergence step number does not need to be modified.
--max-long-edge The maximum length of the long edge. The program automatically scales the input image according to this value. For example, the image above is scaled to a height of 512 pixels. The program execution time and memory consumption are approximately proportional to the area of ​​the image, because the convolutional network's computational power is related to each pixel, and a 700-pixel image is almost twice as memory and runtime as a 500-pixel image. In the following comparison test, you can see that the 512-pixel figure requires almost 1.4GB of video memory. The video card suitable for 2G memory such as the nvidia video card, such as the macbook pro, is enough for entertainment. The 4GB graphics card can handle up to 850-900. The picture of the pixel, in order to want 1080p to have Titan X 12GB. In the same way, the calculation time will be lengthened accordingly, which is also approximately inversely proportional to the number of CUDA cores on the graphics card. Now you basically understand why the free version mentioned above needs to wait in line for hours to weeks.
--Lr The logistic regression's Gradient Descent (SGD) learning rate is used to find the generated image that satisfies both "breaking dog" and "van Gogh" in terms of content. Larger etas converge faster, saving computing time but jumping near the minimum. The default value of 0.1 can be adjusted to both 0.2 and 0.3.
--gpu Use the first few GPUs, the default is 0 GPU, for users with only one graphics card (such as my home machine). If you don't have a GPU and can tolerate about 40 minutes to figure out a graph, --gpu -1 can also be specified as a pure CPU calculation.
--output Output file name.
--save-epochs Whether to save the intermediate result, the default is to save the result every 50 steps.
-remove-noise Noise reduction parameter, default 0.2, can reduce some to 0.15, which is the radius of Gaussian noise reduction. In the process of learning to imitate a painting, the program will use two white noise pictures to approximate the style map and the content map. In the final generated picture, some unnecessary noise points may remain, and the program may reduce noise.
How does the machine imitate drawing styleThe answer to this question is also not clear in the original paper, and the author did not want to explain it clearly. The following discussion is based on my personal and based on the original and reddit and know about the related discussion outlined here, for more discussion, please refer to: reddit Zhihui here together with the authors and commentators in the above link.
Quantify "Painting Style"
“Painting style†is an abstract stereotyped word. It may be related to some kind of high-order statistics of the image, but different styles of painting have different representations. It is difficult for people to use manual methods for a general problem that does not specifically define the style. Design the algorithm to complete. Fortunately, we know that convolutional network CNN can accomplish object recognition by extracting the abstract features of objects through multi-layer convolutions (please refer to Yann Lecun's deep learning tutorial). This ability of “abstract abstract features†is used by the author to describe “ style". In other words, the image after multi-layer CNN abstraction discards pixel-level features while retaining the advanced painting style. The following figure is quoted from the original paper Figure 1. In the article, the author defines a five-tiered CNN network. Van Gogh’s starry sky retains some of the details of the original map as it passes through the first two, but at the fourth and fifth floors it becomes “ It looks like the van Gogh's look like this abstract feature:
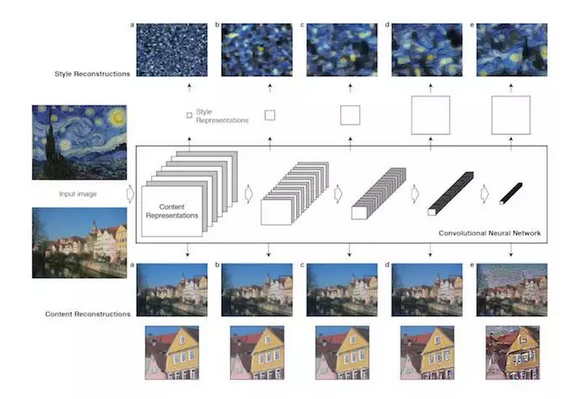
At this time, the author wit thought that if you put a Van Gogh other photo at the same time into the CNN network, after the appropriate adjustments to make the second photo close to Van Gogh on the fourth and fifth floor, and the first two third The layer stays about the same as before, so you can imitate Van Gogh! In detail, the author uses the VGG model of CNN crop recognition to follow the feature abstraction capabilities of CNN.
Learn styles and generate images
So letting the machine imitate the painting style and generate the picture becomes an optimization problem: the generated image should be like the original content picture, for example, the picture I give to a cat must still be like a cat; the generated image should be like a picture of a style, such as I gave a picture of Van Gogh. The pictures of the cats I created should look like Van Gogh's style. That is to say, to find such an intermediate result, its content representation (the first two, three-tier CNN) is close to broken dog, and its style expression (fourth and fifth floor CNN) is close to Van Gogh. In the article, the author uses a white noise picture to generate a picture that is close to the content map by gradient descent, and another white noise picture to produce a picture that is close to the style of the painting picture, and defines a magical gram matrix that describes the texture. The loss functions of the graphs are weighted and averaged as the optimization objective function. In the realization of mxnet, the convergence is achieved by gradient descent (SGD) to find such a content and style with the intermediate result. For example, in the more than 200-step cycle of the "breaking dog" and the "Van Gogh self-portrait" generation process, the image changes are shown in the following diagram: 
We can see that in the first few dozen steps, the picture is more like a simple texture overlay of the original picture and the painting, and as the number of loop steps increases, the program slowly learns the style of color matching and stroke, in 150 steps. The basic shape is left and right, and the picture of the broken dog is finally painted into Van Gogh's style.
Is this the only way to imitate style?Actually not, many papers on computational graphics have made some achievements in various directions. This article only uses deep learning and CNN methods. Other papers with similar learning styles can refer to relevant readings:
"A Parametric Texture Model Based on Joint Statistics of Complex Wavelet Coefficient" http: // This article extracts the second-order statistics corresponding to the "texture" of the image texture using the wavelet transform, and is consistent with the thesis mentioned in this article. of.
"Style Transfer for Headshot Portraits"
Https://people.csail.mit.edu/yichangshih/portrait_web/ This article is about the style of avatar photos. It can learn styles very quickly and it can change the video in real time. For this strictly limited problem, it is faster than Neural art is so high that I don't know where to go.
ConclusionAs an example of deep learning and CNN, Neural art is really fun. Audience friends can use MXnet to generate interesting art pictures for themselves and their friends. Remember to send them to microblogs and share mxnet topics. It is worth reminding that if the original image is a half-length portrait class, it is suggested that some portrait paintings be used to learn the style, such as the combination of “broken dog†and “Van Goghâ€; accordingly, it is best to use landscape painting style to learn landscape images. . Because landscapes are different in expression and portrait, it is not appropriate to force the painting of a portrait into a portrait. It will look like a simple superposition of two pictures. Even a human artist cannot draw together.
Lei Feng Network (search "Lei Feng Network" public number attention) Note: This article has been transferred from big data talk, if you need to reprint, please contact the original author.
More: AI Retouching Art: The Marvelous Algorithm Behind Prisma | Depth
Cmos Fix- Mounted Scanner,Fix Mount Barcode Scanner,Scanner For Conveyor,1D Code Reader Engine
Guangzhou Winson Information Technology Co., Ltd. , https://www.winsonintelligent.com