Electronic enthusiasts eight o'clock early: This article allows you to understand how many technical bottlenecks exist in the current hot artificial intelligence field. In fact, we are far from the true artificial intelligence.
Artificial intelligence can’t be fired anymore. Various news organizations are constantly releasing material. Some say that IBM's Waston artificial intelligence has been able to completely replace workers. Others say that the current algorithm has been able to beat doctors in the medical field. Every day, new artificial intelligence startups emerge, each claiming to be using machine learning to completely subvert your personal life, commercial activities.
There are also products that are commonplace on weekdays, such as juicers and wireless routers. They have also been replaced with new slogans overnight: "We are all supported by artificial intelligence technology!" Smart tables not only know you The right height for working on weekdays can even help you order lunch!

But what is the truth? The reporters who reported the news have never personally intervened in a neural network training process, and the news startups and marketing teams have their own calculations: they want to expand their reputation and gain The attention to capital and talent, even if they do not solve a problem in reality.
It is also in such an embarrassing atmosphere that it is no wonder that there will be so many ignorances in the field of artificial intelligence. In fact, everyone can't figure out what AI can do and what AI can't do.
Deep learning is indeed a fascinating technology, which is irrefutable.
In fact, the concept of neural network has emerged since the 1960s. It is only because of the recent leap in big data and computer performance that it has really become useful, and it has also derived a kind of "deep learning." The specialty is designed to apply complex neural network architectures to data modeling, ultimately leading to unprecedented accuracy.
The current technological developments are indeed impressive. Computers can now recognize what's in the picture and video, and turn voice into text, which is more efficient than humans. Google has also added a neural network to the GoogleTranslate service, and now machine learning is gradually approaching human translation at the translation level.
Some applications in reality are also eye-opening. For example, computers can predict farmland crop yields, which are more accurate than the US Department of Agriculture. Machines can also diagnose cancer more accurately, and its accuracy is better than that of many years. The old doctor is even taller.
John Lauchbury, a director of the DARPA (Advanced Defense Research Program of the US Department of Defense), described three waves in the field of artificial intelligence:
1, the knowledge base, or similar to the "deep blue" and Waston expert system developed by IBM.
2. Data learning, which includes machine learning and deep learning.
3. Situational adaptation, which involves constructing a reliable, interpretive model in real life by using a small amount of data, just as humans can do.
As far as the second wave is concerned, the current research work on deep learning algorithms is progressing well, in the words of Launchbury, because of the emergence of the “manifold hypothesisâ€. (See below)

But deep learning is also a bit of a problem.
At an recent AI conference in the Bay Area, Google's artificial intelligence researcher Francois Chollet emphasized the importance of deep learning, which is more advanced than general data statistics and machine learning methods, and is a very powerful model. Identify tools. However, there is no denying that it has serious limitations, at least for now.
The result of deep learning is based on extremely demanding preconditions
Whether it is “supervised percepTIon†or “reinforcement learningâ€, they all require a lot of data to support, and they perform very poorly in advance planning, and can only do some of the simplest and direct models. Identify the work.
In contrast, people can learn valuable information from a very small number of examples, and are good at planning over a long time span, having the ability to build an abstract model for a situation and using such a model. Do the summary summary of standing at the highest point.
In fact, the most common thing that a passer-by can walk on the street is difficult for deep learning algorithms. Let's take an example: Now let's say that we want the machine to learn how to avoid being hit by a car while walking on the road.
If you are using the “supervised learning pathâ€, then you need to extract a large amount of data from the situation of car driving, and also sort and sort with the clearly labeled “action tagâ€, such as “stopâ€, “stayâ€, etc. Wait. Next, you also need to train a neural network to enable it to build a causal link between the current situation and the corresponding action;
If you are using the "enhanced learning path", then you should give the algorithm a goal to independently determine what the current optimal solution (that is, the best action) is, the computer in different situations, in order to achieve Avoid this action of a crash, it is estimated to take thousands of times on the plane;
Choliet concludes: "You can't achieve some kind of intelligence in the general sense based on the technological developments of today and today."
And people are different, you need to tell him once: you need to avoid the car. Then our brain has the ability to extract experience from a few examples, the ability to imagine the miserable scenes that are crushed by the car in the brain (called “modeling†at the computer), in order to avoid loss of life or lack of arms. With fewer legs, most people can quickly learn the essentials that are not hit by cars.
Although there has been a lot of progress now, some neural networks can give an amazing result from a data level and a large sample size, but if they come out alone, they are all unreliable and committed. Mistakes are impossible for a person to make, for example, mistake the toothbrush as a basket.

The instability of data quality is: unreliable, inaccurate, and unfair.
Moreover, your results depend on how well the data is entered. If the input data in the neural network is inaccurate and incomplete, then the result will be wrong and outrageous, and sometimes it will not only cause losses, but also be embarrassing. For example, Google Pictures mistakes African-Americans as orangutans; Microsoft tried to put an artificial intelligence on Twitter to learn. After a few hours, it became malicious, swearing, and serious. Racial discrimination.
Perhaps this example on Twitter is extreme, but it is undeniable that there is some degree of prejudice and discrimination in the data we input. This subjective, subtle concept or suggestion, sometimes we can’t even aware. For example: word2vec is an open source tool for word embedding launched by Google, which extracts 3 million words from GoogleNews. The information conveyed by this set of data includes “Dad is a doctor, mother is a nurse.†This obviously has gender discrimination.
This kind of discrimination is not only carried out to the digital world, but also amplified. If the word "doctor" points more to "man" than "woman," the algorithm prioritizes men in front of women when faced with an open screening of doctor positions.
In addition to being inaccurate and unfair, there is still the biggest risk: not safe.
Ian Goodfellow, the inventor of "Generation of Confrontational Networks" (GAN), reminds us that the current neural network can be easily manipulated by unscrupulous people. They can tamper with the picture in a way that the human eye cannot recognize, and let the machine mistakenly recognize the picture.
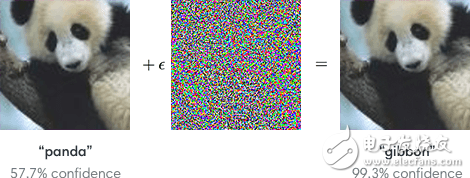
On the left is the panda (the machine's confirmation is 57.7%). After adding the middle picture, the machine's confirmation level has risen to 99.3%, and the gibbons appear on the picture.
Don't underestimate the risk. This malicious tampering with the artificial intelligence system will bring great harm, especially the falsified picture and the original picture are completely different in our opinion. For example, unmanned cars can be threatened. ,
The above are the bottlenecks of deep learning. At present, the preconditions required for its functioning are too harsh. The input data has a decisive influence on its final result. In addition, it has many loopholes and security. Unable to get a guarantee. If we are going to the ideal future of artificial intelligence, these bottlenecks have yet to be further broken and challenged.
Disclaimer: The electronic reprinted works of E-Commerce Network are as far as possible to indicate the source, and all rights of the owner of the work are not transferred due to the reprint of this site. If the author does not agree to reprint, please inform the site to delete or correct it. Reprinted works may be subject to change in title or content.
Shenzhen Esun Herb Co.,Ltd. , https://www.szyoutai-tech.com