Deep learning has so many amazing capabilities! Starting from 12 years of image recognition, deep learning has made breakthroughs, allowing people to refresh their understanding of it again and again. However, the application of deep learning has always had a huge premise: a large amount of labeled data. But if there is less data, can you not enjoy the dividends brought by deep learning? Recently, researchers from Carnegie Mellon University, Amazon Research Institute, and California Institute of Technology presented a variety of methods at the top artificial intelligence conference UAI to try to alleviate or even solve the impact of data sparseness on deep learning.
Main method

In order to solve the problem of insufficient data and sparse data in deep learning, there are currently five mainstream methods in the industry:
Data augmentation
Semi-supervised learning
Transfer learning
Domain adaptation
Active learning
Below, we give a brief introduction to these 5 methods, and a detailed introduction.
Data augmentation

The main purpose of data augmentation is to add various other transformations such as noise to the existing data to generate some meaningful data. Yes, increase the data set to solve the problem of data sparseness and improve the performance of the model. In particular, as shown in the figure, Zachary Lipton introduced one of his recent work: using GAN to do image data augmentation.
Semi-supervised learning

The case of semi-supervised learning means that we have a small number of labeled samples (the orange part in the figure) and a large number of unlabeled samples (the blue part in the figure).
The general idea of ​​semi-supervised learning is: learn data representation on all data, learn models on labeled samples, and use all data to add regularization.
Transfer learning
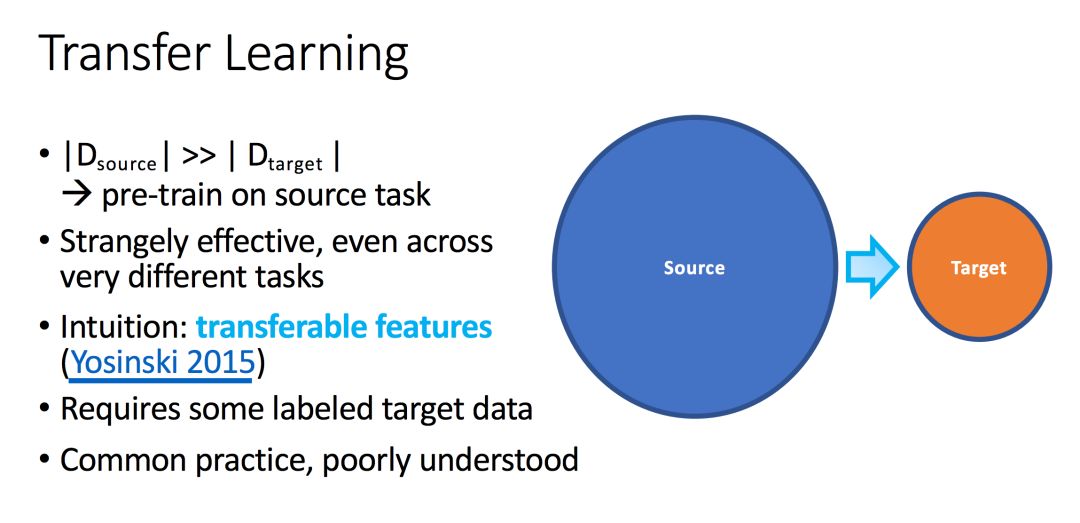
Migration learning is mainly about learning a model on a data with a large number of samples (the blue part in the figure), and in the case of fewer changes, migrating the learned model to similar target data (the orange part in the figure) ) And the task.
Domain adaptation

Domain adaptation is mainly to learn the model on the existing labeled data p(x,y), and then try to apply it on another distribution q(x,y).
Active learning
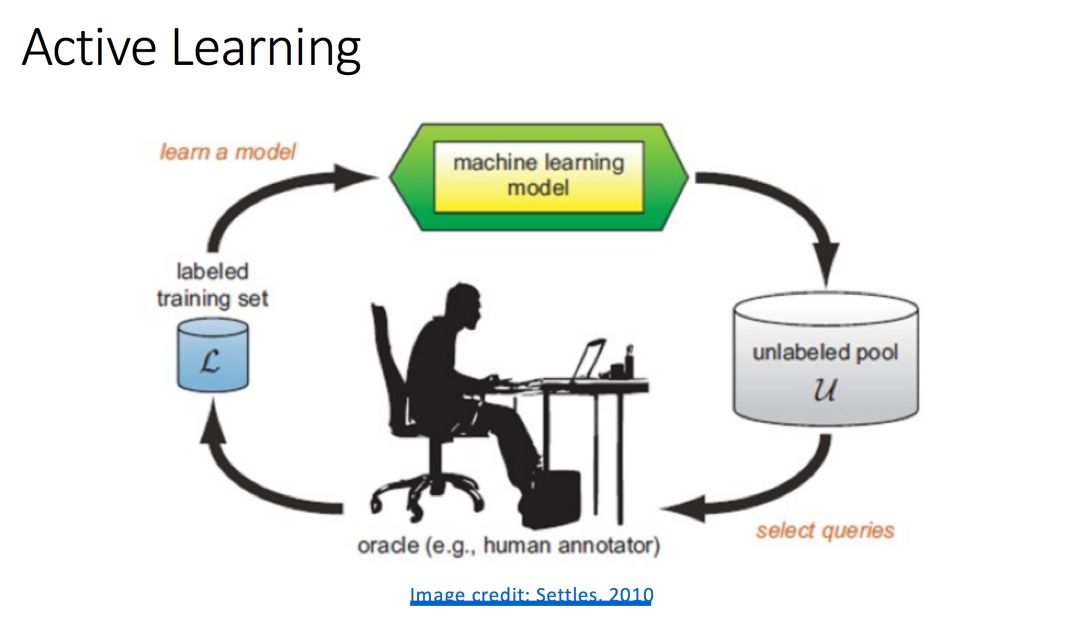
Active learning maintains two parts: learning engine and selection engine. The learning engine maintains a benchmark classifier and uses a supervised learning algorithm to learn the labeled examples provided by the system to improve the performance of the classifier, while the selection engine is responsible for running the sample selection algorithm to select an unlabeled example and It is handed over to human experts for labeling, and then the labeled samples are added to the set of labeled samples. The learning engine and the selection engine work alternately. After multiple cycles, the performance of the benchmark classifier gradually improves. When the preset conditions are met, the process is terminated.
Hall Closed Loop Current Sensor
Hall Closed Loop Current Sensor,Closed Loop Current Sensor,Hall Effect Current Transducers,Closed Loop Hall Current Sensor
Zibo Tongyue Electronics Co., Ltd , https://www.tongyueelectron.com