Based on the accumulation of large amounts of data, the development of deep neural network models and the iterative optimization of algorithms, in recent years, the accuracy of speech recognition has been continuously improved. In October 2016, Microsoft announced that the English speech recognition word error rate dropped to 5.9%, which is comparable to humans. At this stage, in an ideal environment, the voice recognition systems of many companies have crossed the practical threshold and have been widely used in various fields.
The artificial intelligence industry chain consists of a base layer, a technology layer and an application layer. Similarly, intelligent speech recognition is composed of these three layers. This paper starts from the commercial application of speech recognition, and discusses the algorithms and hardware computing capabilities that drive the development of speech recognition. The Trinity analyzes the status quo, development trend and difficulties still facing speech recognition.
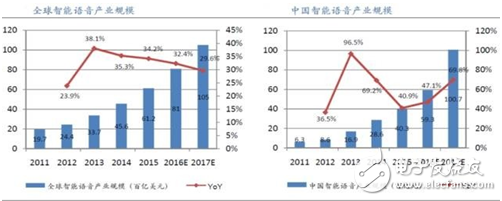
First, the applicationIntelligent voice technology is one of the most mature technologies for artificial intelligence applications, and has the natural nature of interaction. Therefore, it has a huge market space. According to the China Voice Industry Alliance's 2015 White Paper on China's Intelligent Voice Industry Development, the scale of the global intelligent voice industry will exceed US$10 billion for the first time in 2017, reaching US$10.5 billion. China's smart voice industry in 2017 will also exceed 10 billion yuan for the first time, with a compound annual growth rate of more than 60%.
The technology giants are building their own intelligent voice ecosystem. There are IBM, Microsoft, and Google in foreign countries, and Baidu and Keda News in China.
Companies such as IBM, Microsoft, and Baidu use a combined model to improve speech recognition performance in speech recognition. Based on the acoustic model composed of six different deep neural networks and the language model composed of four different deep neural networks, Microsoft has achieved recognition accuracy beyond humans. Based on the deep full-sequence convolutional neural network speech recognition framework, the University of Science and Technology has achieved practical-level recognition performance. Smart Voice Startups such as Yunzhisheng, Jietong Huasheng, and Spirit are constantly polishing their recognition engines and are able to bring their technology to the industry.
Driven by giants and innovators, speech recognition has gradually developed rapidly in the fields of smart homes, smart cars, voice assistants, and robots.
1, smart homeIn the smart home market, especially the smart speaker market, Amazon and Google are in an industry dominance and have their own characteristics.
Amazon's Echo has sold nearly 10 million units, detonating the online smart speaker market. Compared with traditional speakers, Echo has the functions of remotely waking up to play music, querying information online, and intelligently controlling home appliances. However, in terms of smart question and answer, Echo performed in general, and Google used this as a breakthrough to release Google Home and grab 23.8% of the smart speaker market share from Amazon. In September 2017, Amazon released a number of Echo second-generation products, which have a significant improvement in sound quality compared to the previous generation, and Echo Plus has more powerful home control functions, which can automatically search for and install smart home devices. .
In China's language-controlled TV, language-controlled air conditioners, language-controlled lighting and other intelligent language-controlled home appliances market, Keda Xunfei, Yunzhisheng, and Kaiying Tailun made in-depth layout.
Keda Xunfei and JD.com released the speakers, and in 2016 launched the Xunfei TV Assistant to create an entry-level application in the smart home field. Yunzhisheng provides IoT artificial intelligence technology, and cooperates with companies such as Gree to integrate its own speech recognition technology into terminal home appliances. In addition, Yunzhisheng’s 'Pandora' voice control solution can significantly shorten product intelligence. Cycle. Combining its powerful hardware (terminal intelligent speech recognition chip CI1006) and algorithm (deep learning speech recognition engine), Qi Ying Tai Lun provides offline and online complete speech recognition solutions, and has a wide range of layouts in various fields of the Internet of Things.
2, smart carWith the development of intelligent network, it is expected that the penetration rate of the car network in the vehicle end will exceed 50%. However, based on factors such as security, there is a great difference between the smartness of the vehicle end and the intelligence of the mobile terminal. The simple copying method from the mobile terminal is not suitable for the vehicle end use scenario. Based on the natural nature of its interaction, speech is considered to be the main entry path for future human-vehicle interactions.
With its own artificial intelligence ecosystem platform, Baidu launched the smart driving assistant CoDriver. In cooperation with car manufacturers such as Chery, HKUST has launched the Flying Fish Auto Assistant to promote the car networking process. Sogou and NavInfo have launched the Flying Song navigation. Yunzhisheng and Sibichi have launched a variety of intelligent language-controlled car products in navigation applications such as navigation and head-up displays. Going out to ask questions is based on his own questioning magic mirror to enter the smart car market.
In the commercialization of speech recognition, collaborative support of content, algorithms and other aspects is needed, but a good user experience is the first element of business application, and the recognition algorithm is the core factor to enhance the user experience. In the following, the speech recognition technology will be discussed from three aspects: speech development algorithm development path, algorithm development status and frontier algorithm research.
Second, the algorithmFor speech recognition systems, the first step is to detect if there is voice input, ie, voice activation detection (VAD). In low-power designs, VAD uses the always on mechanism of operation compared to other parts of speech recognition. When the VAD detects a voice input, the VAD wakes up the subsequent recognition system. The overall process of the identification system is shown in Figure 2. It mainly includes several steps of feature extraction, recognition modeling and model training, and decoding to obtain results.
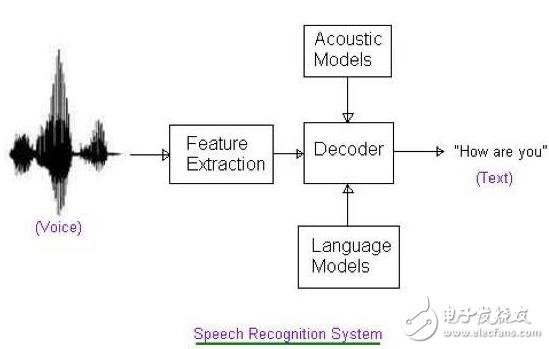
Figure 2. Speech recognition system
1, VAD (voice activation detection)Used to determine when there is voice input and when it is muted. Subsequent operations of speech recognition are performed on valid segments taken out by the VAD, thereby reducing the false recognition rate of the speech recognition system and the system power consumption. In the near-field environment, due to the limited attenuation of the speech signal, the signal-to-noise ratio (SNR) is relatively high, and only a simple method (such as zero-crossing rate, signal energy) is needed for activation detection. However, in the far-field environment, since the speech signal transmission distance is relatively long and the attenuation is relatively serious, the SNR of the microphone acquisition data is very low. In this case, the simple activation detection method is ineffective. The use of deep neural network (DNN) for activation detection is a method commonly used in deep learning speech recognition systems (under which speech activation detection is a classification problem). A simplified version of DNN is used in MIT's intelligent speech recognition chip to do VAD. This method also has good performance in the case of relatively loud noise. But in a more complex far field environment, VAD is still the focus of future research.
2, feature extractionThe Mel Frequency Cepstral Coefficient (MFCC) is the most commonly used speech feature, and the Mel frequency is extracted based on the human auditory characteristics. MFCC is mainly composed of pre-emphasis, framing, windowing, fast Fourier transform (FFT), mel filter bank and discrete cosine transform. FFT and mel filter are the most important parts of MFCC. However, recent studies have shown that the Meyer filter bank is not necessarily the optimal solution for speech recognition. Deep neural network models such as restricted Boltzmann machines (RBM), convolutional neural networks (CNN), and CNN-LSTM-DNN (CLDNN) are used as a direct learning filter instead of the Mel filter bank for automatic learning. The speech feature is extracted and achieved good results.
It has been proved that CLDNN has obvious performance advantages over log-Mel filter banks in feature extraction. The feature extraction process based on CLDNN can be summarized as follows: convolution, pooling, and pooled signals on the time axis enter the CLDNN in three steps.
In the field of far field speech recognition, microphone array beamforming is still the dominant method due to problems such as strong noise and reverberation.
In addition, at this stage, the beamforming method based on deep learning has also achieved many research results in automatic feature extraction.
3. Identification modelingSpeech recognition is essentially a process of audio sequence to text sequence conversion, that is, in the case of a given speech input, the most probable sequence of words is found. Based on the Bayesian principle, the speech recognition problem can be decomposed into the conditional probability of the speech appearing in a given text sequence and the prior probability of the sequence of the character appearing. The model modeled on the conditional probability is an acoustic model. The model obtained by prior probabilistic modeling of a sequence of texts is a language model.
3.1 Acoustic model
An acoustic model is an output that converts speech into an acoustic representation, that is, the probability that a given speech originates from an acoustic symbol. For acoustic symbols, the most direct expression is a phrase, but in the case of insufficient training data, it is difficult to get a good model. A phrase is composed of consecutive pronunciations of multiple phonemes. In addition, phonemes are not only clearly defined but also limited in number. Thus, in speech recognition, the acoustic model is usually converted into a model of a speech sequence to a pronunciation sequence (phoneme) and a dictionary of pronunciation sequences to output text sequences.
It should be noted that due to the continuity of human vocal organ movements and the specific spelling habits of certain languages, the pronunciation of phonemes is affected by the phonemes before and after. In order to distinguish between phonemes of different contexts, a triphone that can consider one phoneme before and after is usually used as a modeling unit.
In addition, in the acoustic model, the triphones can be decomposed into smaller particle-states, usually one triphone corresponds to three states, but this causes an exponential increase in the modeling parameters. A common solution is to use a decision tree. These triphone models are clustered first, and then the results of clustering are used as classification targets.
At this point, speech recognition has the ultimate classification target - state. The most common method of acoustic modeling is the Hidden Markov Model (HMM). Under HMM, the state is a hidden variable, the speech is an observation, and the jump between states conforms to the Markov assumption. Among them, the state transition probability density is mostly modeled by geometric distribution, and the model for fitting the hidden variable to the observed probability of the observation is commonly used in the Gaussian mixture model (GMM). Based on the development of deep learning, models such as deep neural network (DNN), convolutional neural network (CNN), and cyclic neural network (RNN) were applied to the modeling of observation probability and achieved very good results. The principles of each model, the problems solved and their respective limitations are given below, and the context of the development of the modeling method caused by the limitations of the model is given.
1) Gaussian Mixture Model (GMM)
The observed probability density function is modeled by a Gaussian mixture model. During training, iterative optimization is performed to obtain the weighting coefficients in the GMM and the mean and variance of each Gaussian function. The GMM model has a faster training speed, and the GMM acoustic model has a small amount of parameters and can be easily embedded in the terminal device. For a long time, the GMM-HMM hybrid model is the best performing speech recognition model. However, GMM cannot use context information and its modeling capabilities are limited.
2) Deep Neural Network (DNN)
The earliest neural network used for acoustic model modeling, DNN solved the inefficiency problem of data representation based on Gaussian mixture model. In speech recognition, the DNN-HMM hybrid model greatly improves the recognition rate. At this stage, DNN-HMM is still a common acoustic model in the specific speech recognition industry based on its relatively limited training cost and high recognition rate. It should be noted that based on the constraints of the modeling method (the consistency requirement of the model input feature length), the DNN model uses a fixed-length sliding window to extract features.
3) Recurrent Neural Network (RNN)/Convolutional Neural Network (CNN) Model
For different phonemes and speech rates, the feature window lengths that utilize context information are different. RNN and CNN that can effectively utilize variable-length context information can achieve better recognition performance in speech recognition. Thus, in terms of speech rate robustness, CNN/RNN performs better than DNN.
In terms of using RNN modeling, models for speech recognition modeling include: long-short-term memory network (LSTM) with multiple hidden layers, highway LSTM, ResidualLSTM, bidirectional LSTM, and bidirectional LSTM for delay control.
LSTM, based on gated circuit design, is able to take advantage of long and short time information and achieves very good performance in speech recognition. In addition, the recognition performance can be further improved by increasing the number of layers, but simply increasing the number of layers of the LSTM causes training difficulties and gradient disappearance problems.
Highway LSTM adds a gated direct link between memory cells in adjacent layers of the LSTM to provide a direct and non-attenuating path for information flow between layers, thus solving the gradient disappearance problem
The Residual LSTM provides a shortcut between the LSTM layers and also solves the gradient disappearance problem.
Two-way LSTM, which can utilize past and future context information, so its recognition performance is better than one-way LSTM, but since the bidirectional LSTM utilizes future information, the speech recognition system based on bidirectional LSTM modeling needs to observe a complete paragraph. It can then be identified and is not suitable for real-time speech recognition systems.
Delay-controlled bidirectional LSTM, by adjusting the reverse LSTM of the bidirectional LSTM, implements a compromise modeling solution for performance and real-time performance, which can be applied to real-time speech recognition systems.
CNN modeling, including time delay neural network (TDNN), CNN-DNN, CNN-LSTM-DNN (CLDNN), CNN-DNN-LSTM (CDL), deep CNN, layer-by-layer context extension and attention (LACE) CNN , dilated CNN.
TDNN, the earliest used CNN modeling method for speech recognition, TDNN convolves simultaneously along the frequency axis and the time axis, so it can utilize variable-length context information. There are two cases in which TDNN is used for speech recognition. In the first case: only TDNN is difficult to use for large vocabulary continuous speech recognition (LVCSR) because of variable length expression (utterance) and variable length Context information is two different things. In LVCSR, variable length representation problem needs to be dealt with, while TDNN can only process variable length context information. The second case: TDNN-HMM hybrid model, because HMM can handle variable length representation problem, Therefore, the model can effectively deal with the LVCSR problem.
CNN-DNN adds one or two layers of convolutional layer before DNN to improve the robustness of different speakers' vocal tract problems. Compared with simple DNN, CNN-DNN has certain performance. Increase in range (5%)
CLDNN and CDL, in these two models, CNN only deals with changes in the frequency axis, and LSTM is used to utilize variable-length context information.
Depth CNN, where "depth" refers to more than one hundred layers. Spectrograms can be viewed as images with specific patterns, using relatively small convolution kernels and more layers to exploit long-range correlation information over time and frequency axes, modeling performance and bidirectional for deep CNN LSTM performance is comparable, but deep CNN has no latency issues. In the case of controlling the computational cost, the deep CNN can be well applied to real-time systems.
Layer-by-layer context extension and attention (LACE) CNN and classified CNN, the calculation of deep CNN is relatively large, so LACE CNN and classified CNN which can reduce the calculation amount are proposed, which regards the whole utterance as a single input map. The intermediate results can be reused. In addition, the computational cost can be reduced by designing the step size of each layer of the LACE CNN and the dilated CNN network to cover the entire core.
The application environment of speech recognition is often complicated. Selecting model modeling acoustic models that can cope with various situations is a common modeling method in industry and academia. But each single model has limitations. The HMM can handle variable length representations, CNN can handle variable channels, and RNN/CNN can handle variable context information. In acoustic model modeling, the hybrid model is the mainstream way of acoustic modeling because it can combine the advantages of each model.
3.2 Language Model
The most common language model for speech recognition is N-Gram. In recent years, the modeling methods of deep neural networks have also been applied to language models, such as language models based on CNN and RNN.
4, end-to-end speech recognition systemIn the DNN-HMM or CNN/RNN-HMM model, DNN/CNN/RNN is optimized separately from HMM, but speech recognition is essentially a sequence identification problem. If all the components in the model can be jointly optimized, it is likely that To obtain better recognition accuracy, this can also be seen from the mathematical expression of speech recognition (using the expression after the Bayesian criterion change), so the end-to-end processing is also introduced into the speech recognition system.
4.1 CTC Guidelines
The core idea is to introduce a blank tag and then do a sequence-to-sequence mapping based on the forward-backward algorithm. The CTC criteria can be divided into character-based CTC, other output units-based CTC, and word-based CTC. Since the CTC criterion is to directly predict characters, words, etc., rather than predicting phonemes, it can eliminate expert knowledge such as dictionaries in speech recognition. . Because in non-word-based CTC, language models and decoders are still needed. Thus, character-based CTC and other output units-based CTC are non-pure end-to-end speech recognition systems. In contrast, the word-based CTC model is a pure end-to-end speech recognition system.
Based on the word-based CTC criterion, a model of a phonetic sequence-to-word sequence using 100,000 words as an output target and using 125,000 hours of training samples can transcend the phoneme-based model. However, the word-based CTC model has difficulties in training and slow convergence.
4.2 AttenTIon-based model
Compared to the CTC guidelines, the AttenTIon-based model does not require inter-frame independence assumptions, which is a major advantage of the AttenTIon-based model, so the AttenTIon-based model may be able to achieve better recognition performance. However, Attention-based model training is more difficult than CTC guidelines, and has the disadvantage of not being able to unilaterally align from left to right and converge more slowly. Attention training and CTC training are combined in a multitasking approach by using the CTC objective function as an auxiliary cost function. This training strategy can greatly improve the convergence of the Attention-based model and alleviate the alignment problem.
Deep learning plays a key role in the development of speech recognition. Acoustic models follow a development path from DNN to LSTM to end-to-end modeling. One of the biggest advantages of deep learning is characterization. In the case of noise, reverberation, etc., deep learning can regard noise and reverberation as new features, and achieve better recognition performance by learning noise and reverberation data. At the current stage, end-to-end modeling is the key research direction of acoustic model modeling, but it has not achieved significant performance advantages compared to other modeling methods. How to improve training speed and performance and solve convergence problem is an important research direction of acoustic model based on end-to-end modeling.
5, decodingBased on the trained acoustic model, combined with the dictionary and the language model, the process of recognizing the input speech frame sequence is the decoding process. Traditional decoding is the compilation of acoustic models, dictionaries, and language models into a network. Decoding is the selection of one or more optimal paths as the recognition result (the optimal output character sequence) based on the maximum a posteriori probability in this dynamic network space. A commonly used method of searching is the Viterbi algorithm. For an end-to-end speech recognition system, the simplest decoding method is the beam search algorithm.
6, the far field complex environment solutionAt this stage, in the near-field quiet environment, speech recognition can achieve very good recognition results, but in high-noise, multi-person speech, strong accent and other environments, especially in the far-field environment, there are still many problems in speech recognition. Speech model adaptation, speech enhancement and separation, and recognition model optimization are common alternative solutions.
6.1 Speech Enhancement and Separation
In the far field environment, the speech input signal attenuation is more serious. In order to enhance the speech signal, the beamforming technology of the microphone array is often adopted. For example, Google Home adopts the design scheme of the dual wheat, and the Amazon Echo adopts the 6+1 microphone array design scheme. In recent years, the deep learning method has been applied to speech enhancement and separation. The core idea is to transform speech enhancement and separation into a supervised learning problem, that is, to predict the input sound source. Some studies have used DNN instead of beamforming to achieve speech enhancement, and achieved ideal results in certain scenarios. However, in an environment with a large background noise, there is still much room for improvement in the performance of this method.
In the case of multiple people speaking, if the input signal is not separated and speech recognition is performed, the recognition effect will be poor. For this problem, beamforming is a better solution when the distance between multiple speakers is far, but when the distance between multiple speakers is very close, the speech separation effect of beamforming is also poor. In order to avoid the problem of scene classification caused by beamforming, the traditional methods mostly try to solve this problem in a single channel. Common algorithms include computational auditory scene analysis, non-negative matrix decomposition, deep clustering, etc., but these methods only work as noise. These techniques achieve better results when the signal (other than the source) has significantly different characteristics than the source signal. In other cases, these methods achieve a general effect in speech separation. In 2016, Dr. Yu Dong proposed a new deep learning training criterion, permutation invariant training, which skillfully solved the problem and achieved good results.
6.2 Speech Model Adaptation
A large and rich set of data that can provide more information is the most straightforward way to improve the generalization of the model;
Based on cost and training time considerations, only limited training data is generally used. At this point, adding the Kullback-Leiblerdivergence regular term to the model training is a very effective way to solve the model adaptation problem;
In addition to adding regular terms, using very few parameters to characterize speaker features is another adaptive approach, including: singular value decomposition bottleneck adaptation, decomposing the full rank matrix into two low rank matrices, and reducing training parameters. Subspace method, subspace method includes:
1. Add auxiliary features such as i-vector, speaker encoding, noise estimation, etc. to each layer of the input space and depth network;
2. Cluster adaptive training (CAT);
3. Hidden Layer Decomposition (FHL), FHL only requires a small amount of training data compared to CAT, because the base of FHL is a matrix of rank 1, and the base of CAT is a full rank matrix, in the case of the same number of bases. CAT needs more training data.
Real-time performance is one of the most concerned issues in speech recognition applications. Real-time performance directly affects the user's experience. Improving the real-time performance of speech recognition can be achieved by reducing the computation time cost and improving the recognition hardware computing capability.
7, reduce the cost of computing timeSVD, based on the mathematical principle of singular value decomposition, decomposes the full rank matrix into two low rank matrices, reduces the parameters of the depth model, and can not reduce the model recognition performance;
Compression model, using vector quantization or very low bit quantization algorithm;
Change the model structure, mainly for LSTM, add a linear mapping layer in LSTM, reduce the output dimension of the original LSTM, and reduce the computation time cost;
Use cross-frame correlation to reduce the frequency of evaluating deep network scores. For DNN or CNN, this can be done by using a frame skipping strategy, ie calculating the acoustic score every few frames and copying the score when decoding To the frame where the acoustic score is not evaluated.
In addition, to improve the computing power of the identification phase hardware, the development of a dedicated speech recognition chip is of great significance for enhancing the real-time performance of speech recognition, which will be discussed in the following.
Third, the chipThe continuous accumulation of high-quality big data and deep learning algorithms is the key to the continuous improvement of speech recognition performance. The core processing chip of the base layer is a key element supporting massive training data, complex deep network modeling methods, and real-time inference. Speech recognition includes two parts: training and recognition (given the trained model and the input speech).
In the training phase, due to the huge amount of data and the amount of calculation, the traditional CPU or single processor can hardly complete a model training process alone. (In the initial stage, the Google brain speech recognition project is based on 16000 CPUs, which took 75 days to complete one. There is a 156M parameter for deep neural network model training work). The reason is that there are only a small number of logical operation units in the CPU chip architecture, and the instruction execution is a serial process one after another, and its computational power is insufficient. The development of chips with high computing power has become the trend of speech recognition and even the entire artificial intelligence hardware.
Unlike CPUs, GPUs have a large number of computational units and are therefore particularly well suited for massively parallel computing. In addition, FPGAs, TPUs, and ASICs that continue the traditional architecture are also widely used in massively parallel computing. It should be noted that, essentially, these chips are the result of computational performance and flexibility/universal trade-off, ie, as shown in Figure 3. CPU, GPU is a general-purpose processor, DSP is classified as ASP, TPU is ASIC, and FPGA is a Configurable Hardware.
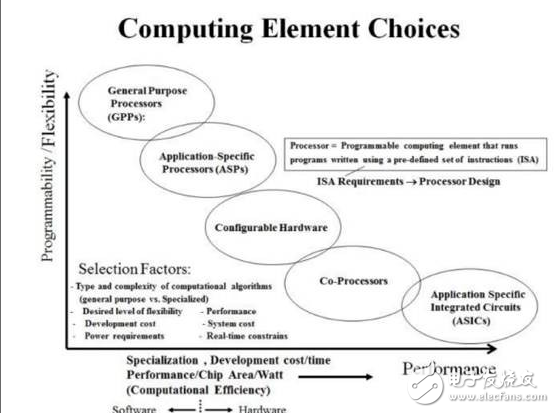
In addition, based on the requirements of real-time, low power consumption and high computing power, a large number of matrix operations in the recognition stage are processed by using a dedicated speech recognition AI chip, and the operation acceleration is the mainstream direction of the terminal speech recognition chip market in the future.
1, cloud sceneDue to the large amount of calculation and training data, and the need for a large number of parallel operations, the current model training part of speech recognition is basically carried out in the cloud. In cloud training, NVIDIA's GPU dominates the market, and multi-GPU parallel architecture is a common infrastructure solution for terminal training. In addition, Google uses TPU for training and recognition in its own artificial intelligence ecosystem.
At this stage, the recognition part of the speech recognition company is mostly placed in the cloud, such as Google home, Amazon Echo, domestic Science and Technology News, Yunzhisheng and so on. In the cloud identification, although the GPU is also used, the GPU is not the optimal solution, and more is to utilize the respective advantages of the CPU, GPU, and FPGA, and adopt a heterogeneous computing solution (CPU+GPU+FPGA/ASIC).
2, the terminal sceneIn the application of smart home and other industries, there are extremely high requirements for real-time, stability and privacy. Due to the consideration of cloud data processing capabilities, network latency and data security, the edge computing that decentralized computing into the terminal hardware has been rapidly developed. Endpoint offline speech recognition is an edge intelligence based on edge computing. We believe that offline and online are the development paths of speech recognition coexistence. In offline identification of the terminal, the trained model needs to be stored in the chip. Given a speech input, the engine calls the model to complete the recognition. The two key factors of terminal speech recognition are real-time and cost, in which real-time affects the user experience, and the cost affects the range of speech recognition applications.
Because deep neural network has obvious performance advantages in speech recognition, it is the current mainstream speech recognition modeling method. However, the model parameters of the neural network are generally very large, and there are a large number of matrix calculations in the recognition process. The commonly used DSP or CPU requires a lot of time to deal with the problem, and thus cannot meet the real-time requirement of speech recognition. The price of GPU and FPGA is the main obstacle that hinders its large-scale application in terminal speech recognition. Considering that the terminal application is relatively fixed and requires high computational performance, the development of a speech recognition dedicated chip is a development trend of the terminal speech recognition hardware.
ChipIntelli: Established in Chengdu in November 2015. In June 2016, the world's first artificial intelligence-based speech recognition chip CI1006 was introduced. The chip integrates neural network acceleration hardware, which can realize single chip, local offline, large vocabulary recognition, and the recognition rate is significantly higher than traditional terminal speech recognition. Program. In addition, Qi Ying Tai Lun can provide a cheap single-field far-field speech recognition module, the actual recognition effect can be comparable to the use of Conexant noise reduction module dual-use module, greatly reducing the cost of far-field speech recognition module. Qi Ying Tai Lun has achieved obvious technical and first-mover advantages in the development of terminal-specific speech recognition chips.
MIT project: MIT Black Technology, the chip in paper published by MIT at ISSCC2017, which can support DNN computing architecture, perform high-performance data parallel computing, and realize thousands of words on a single chip offline.
Yunzhisheng: Yunzhisheng is committed to building a “cloud-end core†voice ecosystem service system. It has just acquired an investment of 300 million yuan and will invest part of the funds into the research and development of the terminal voice recognition chip “UniOneâ€. According to reports, the chip A DNN processing unit will be built in, compatible with multiple microphone arrays.
Speech recognition technology has continued to make breakthroughs in the past few decades, especially in recent years. However, in most scenarios, speech recognition is far from perfect. Solving the problem of speech recognition in far-field complex environment is still a hot topic of current research. In addition, in general, speech recognition is a specific task for training specific models, and thus the portability of the model is relatively poor.
Humans can use prior knowledge very efficiently in the dialogue process, but the current speech recognition system can not effectively use prior knowledge. Therefore, there are still many problems to be solved in speech recognition. Excitingly, with the continuous accumulation of high-quality data, continuous breakthroughs in technology and increased computing power of hardware platforms, speech recognition is rapidly developing in the direction we are looking forward to.
CHENGRONG travel Portable Laptop Stand is a Laptop Foldable Laptop Stand which you can fold and carry easly in your backpack or briefcase you can use It to change angle of your laptop.

Computer Stand Riser,Mesh Monitor Stand Riser,Gold Monitor Stand Riser,Shelf Monitor Stand Riser
Shenzhen ChengRong Technology Co.,Ltd. , https://www.laptopstandsuppliers.com