On September 9, the 2016 Hunan Artificial Intelligence Forum was held in Changsha. During the conference, many top experts from home and abroad gave us a report at the conference. The following is a briefing by Lei Fengnet (search for “Lei Feng Net†public number) according to Microsoft Asia. Professor Liu Tieyan of the Institute has arranged the essence of the site, and all the contents have been confirmed by Professor Liu.
As artificial intelligence advances and people expect deep learning to be invincible, as an artificial intelligence scholar, we must keep calm, analyze the shortcomings of deep learning technology, conduct targeted research to overcome it, and thus contribute to the long-term prosperity of artificial intelligence. In fact, the main factors for success in deep learning today are: large-scale training data, complex deep models, and distributed parallel training, which are also obstacles that affect its further development. First of all, it takes a lot of money to obtain a large amount of labeled training data. Not every field can satisfy this condition. Second, the deep model is difficult to optimize. The oversized model will break through the capacity of the computer. Third, synchronous parallel inefficiencies and asynchronous parallel communication delays. The effect is slow to converge. In this report, I will introduce the latest achievements of Microsoft Research. I will show how to effectively use unlabeled training data through "Dual Communication Game Technology" and how to use "residual learning techniques" to solve deep neural network optimization problems and how to use them. "Two-dimensional mapping technology" reduces the model size and how to use "high-order Taylor compensation technology" to solve the communication delay problem. These cutting-edge technologies will be shared with the industry through Microsoft’s open source projects CNTK and DMTK, with a view to promoting the further development of artificial intelligence technology with everyone.
Dr. Liu Tieyan, Principal Research Fellow, Microsoft Research Asia, Visiting Professor, Carnegie Mellon University (CMU), USA. Dr. Liu’s research interests include: Artificial Intelligence, Machine Learning, Information Retrieval, Data Mining, etc. His avant-garde work promoted the integration of machine learning and information retrieval, and was recognized by the international academic community as a representative of the "ordered learning" field. His academic papers in this field have been cited nearly ten thousand times. In recent years, Dr. Liu has also made achievements in game machine learning, deep learning, distributed machine learning, etc. His research work has won best paper awards, highest cited paper awards, research breakthrough awards and has been widely used in many fields. Microsoft's products and online services. He is a senior member of the Institute of Electrical and Electronics Engineers (IEEE), the American Computer Society (ACM) and the Chinese Computer Society (CCF), and an outstanding speaker and academic working committee of the Chinese Computer Society.

Before I start my report, I will first introduce the organization I work for: Microsoft Research, which is a global research institute established by Microsoft and has six branch offices around the world. The Microsoft Asia Research Institute in Beijing was established in 1998 and has been in existence for 18 years. In the 18 years, Microsoft Research Asia has published nearly 5,000 papers in top international conferences and journals, including 50 articles. Good papers provided 400 technologies for Microsoft products. Microsoft Research Asia is very much like a university, with nearly 200 top computer scientists in the world, and three or four hundred long-term interns from various universities.
Artificial intelligence has made remarkable achievements recently. Microsoft has also made many contributions in this process. For example, breakthroughs in speech recognition originated from research conducted by Microsoft researchers and Geoff Hinton in 2006. Over the past few years, artificial intelligence has achieved research results in human face recognition, image recognition, natural language processing, and interpersonal chess that have exceeded the human level. This is very gratifying.
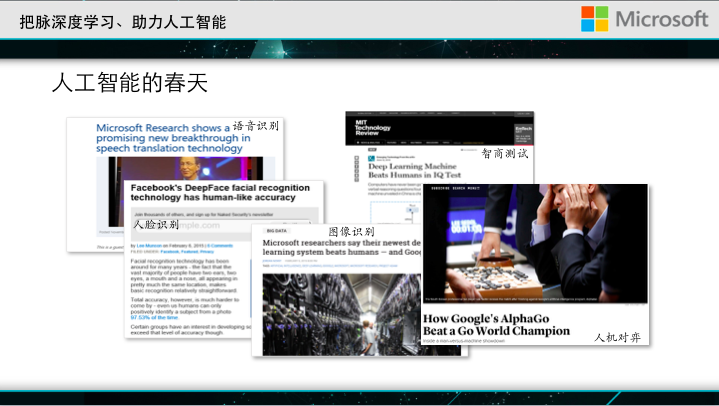
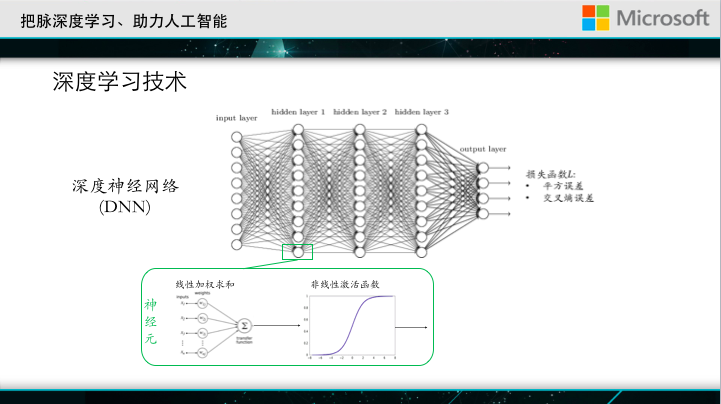
Speaking of the achievements made in recent years, we must mention deep learning technologies. The concept of deep learning technologies is very broad, but the most popular algorithm is the deep neural network . This figure shows the basic structure of deep neural networks. The circle in the graph represents a neuron. Each neuron makes a linear weighted summation of its input, performing a nonlinear transformation. After multiple layers of transformation, deep neural networks can model very complex nonlinear classification interfaces.
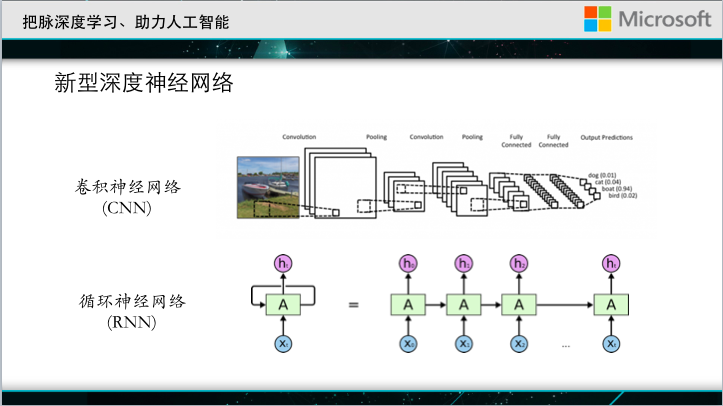
In addition to the most basic full-connection networks, there have been many new variants of deep neural networks recently, such as convolutional neural networks, which invent new network structures for image recognition, and neural networks whose recurrent neural networks are mainly developed for natural language streaming data. structure.
Whether it is a standard multi-layer neural network, a convolutional neural network, or a recurrent neural network, the learning process is very simple and consistent. First there will be a training set. We use w to represent the parameters in the deep neural network and f to represent the neural network model.

L is called the loss function, and the training of deep learning neural network is actually obtained by minimizing the loss function on the training set, which is what we usually call empirical risk minimization. In order to achieve this goal, the optimization techniques people use are also very simple, that is, when you are freshmen, you will learn the gradient descent method: find a gradient for the loss function, and then update the model to the fastest gradient. This method is also known as back propagation in the field of neural networks.

So far I gave everyone a very quick lecture with one or two PPTs. What is a deep neural network and what variations it has.
Why Deep Learning Network succeededNext, let's take a look at the deep layers behind neural networks. When deep neural networks bring a big leap forward in artificial intelligence, what laymen talk about is whether artificial intelligence will threaten humans? What the insider sees is a short version of what the depth of neural network technology has and what it looks like.
As mentioned earlier, no matter what the depth of the neural network looks like, it is actually an empirical risk minimization. Here, X is a sample and Y is a label, so X and Y add up to be training data for the neural network, F to represent the neural network model, and L is a loss function. The neural network training is to find an optimal model in the function space of the entire neural network so as to best fit the training data. In fact, not only neural networks are doing this, but so many classification models in history are doing similar things.

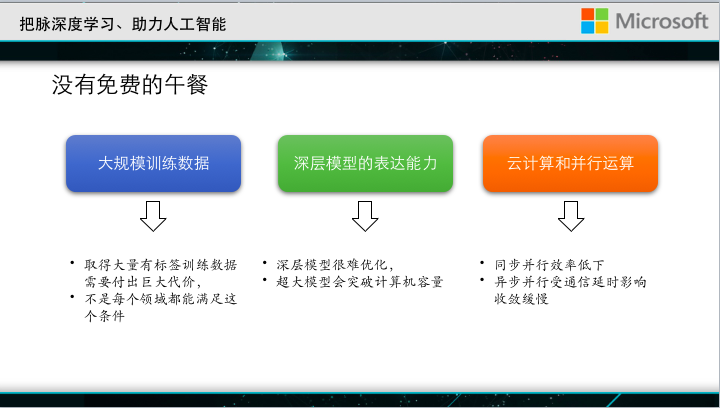
Why is it that today's neural networks can achieve success that cannot be achieved with traditional models? There are actually three reasons:
One is to thank us for this era of big data. We now have unprecedented large training data and can fully train complex models.
The second is that deep neural networks are more expressive than the aforementioned models. We all know that there is a universal approximation theorem in the field of neural networks. It is said that neural networks with hidden layers can approximate any continuous function. In this sense, even if we choose a very complex problem, we can use a deep neural network to approach its classification interface.

With big data and complicated models, how do you train? It requires very powerful computing resources. It is possible to use hundreds of computers and thousands of computers to train a deep neural network together. To sum up, ah, big data, complex models, and computing cluster capabilities actually support the great success of deep neural networks today.
The bottleneck of further development of deep learningHowever, there is no free lunch in the world. These three aspects are also the bottleneck for the further development of the deep neural network.
In the first area, in fact, large-scale data is not so easy to obtain. In particular, in some areas, such as medicine, there are a few samples of some incurable diseases in the world. How to generate thousands of large ones? data?
The second aspect of deep neural networks is very difficult to optimize. At present, people have invented many black technologies. We often encounter this situation, even if an organization has announced that he has a very good depth model and has made the algorithm open source, but when we download it into our own environment and use our own data for training, we often don’t get it. So good results. In addition, sometimes the large model capacity will exceed the computer limit. At present, we often use GPUs to train deep neural networks, but the GPU's memory is very small, generally tens of G, and the size of many large neural networks will exceed This capacity.
In the third aspect, even if the neural network model can be plugged into the GPU, when the data is large enough, training with a single machine may take a lot of time, and maybe a model may not be trained for hundreds of years. For this reason, we need to use a cluster to do distributed training. It sounds very simple, it seems to be a mature problem in the field of systems, but we are not concerned with simply distributing model training to multiple machines, but to ensure accuracy. There is no loss. We hope that at the same time as speeding up, there is still good discrimination or classification ability. This matter is not at all simple.
I) Effective use of unlabeled training data through "Dual Communication Gaming Technology"
As mentioned earlier, in many cases, it is not so easy to get big data. What should I do when there is no large training data? It is often difficult to obtain tagged data, but obtaining untagged data can be relatively rewarding. For example, now the ImageNet competition data is usually 1000 categories, each type of 1000 images; but if we use the search engine to search for images, you can get much more data than this. The key question is how to tag these untagged data. The commonly used method is label propagation, which uses the similarity of samples to assign a pseudo-label to untagged data. In the other case, we have category information but no sample. There is a very interesting work recently called GAN: generative adversarial nets, which uses a generator and a discriminator game to automatically generate data belonging to this category based on tags.
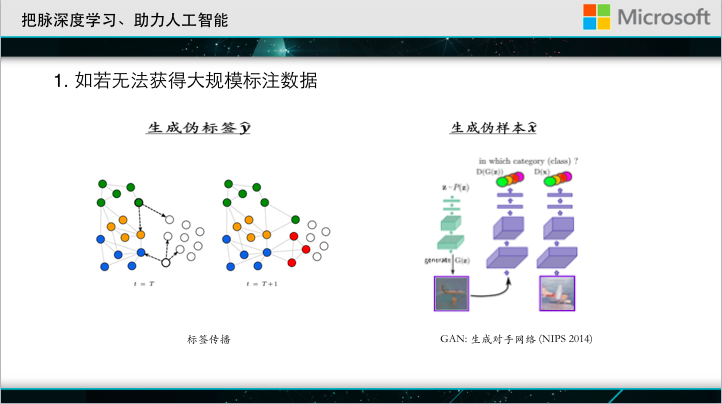
With this technology, we do not have to collect data , but we automatically source those images.
The two jobs are symmetrical. One job deals with samples but no tags, and the other deals with tags but no samples. Can you connect them together? This is a paper that we sent out this year at NIPS. It is called the dual communication game. It can combine the first two technologies perfectly.

Starting from any unlabeled sample, we can predict the label. Then we can generate a new sample based on the label. We can get a lot of feedback information, such as the distribution of the label, the generated sample, and the similarity of the original sample. Degree and so on. This process can also start from the label, it can also form a closed loop. With this technology, we can generate training data ourselves. We applied this technique to machine translation and achieved very good results. We all know that machine translation has made rapid progress in recent years. Thanks to the existence of a large amount of bilingual corpus, what if only a few data can be done?
The uppermost bar chart on this map corresponds to the results of training with 100% bilingual corpus. The bottom line is the result of using only 5% bilingual corpus using traditional deep learning techniques. The green one only uses 5% of the marked data, but using the dual communication game to automatically generate more training data, it can quickly approach the accuracy of using all bilingual corpus. Of course, machine translation is just an example here, and the same method can solve many other application problems.
B) Using "Residual Learning Technology" to Solve the Optimization of Deep Neural Networks
The network of deep learning is complex and training is not easy. So what is not easy?
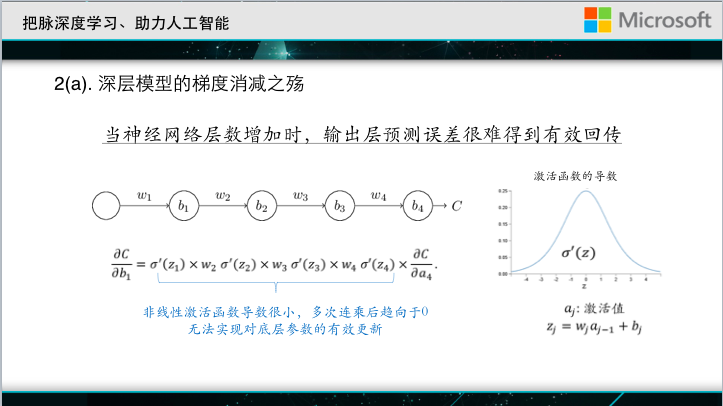
A typical challenge is called gradient reduction. The deep neural network propagates downward from the loss function of the output layer and uses the prediction error to change the parameters of the neural network. The so-called gradient reduction refers to the loss of the output layer when the network is very deep. It is difficult to effectively feed back to the bottom layer, so the underlying neural parameters cannot be effectively updated. We give a simple example. This is a simplified deep neural network. Each layer has only one hidden node, but there are many levels. C is the loss function. Back propagation is nothing more than seeking a partial derivative of the loss function. A layer of parameters to go above, this partial guide looks like long, if you go back and do a little calculation, then you can get this formula. Here sigma' corresponds to the derivative of the nonlinear activation function, and its maximum value is only 0.25. If a network is very deep, the derivative of each layer's corresponding activation function will be multiplied, and a series of very small quantities will be What is the result of this is that it quickly approaches 0, which is the cause of gradient reduction. In order to solve this problem, it is proposed to add a linear path controlled by a gate circuit based on the original neural network.
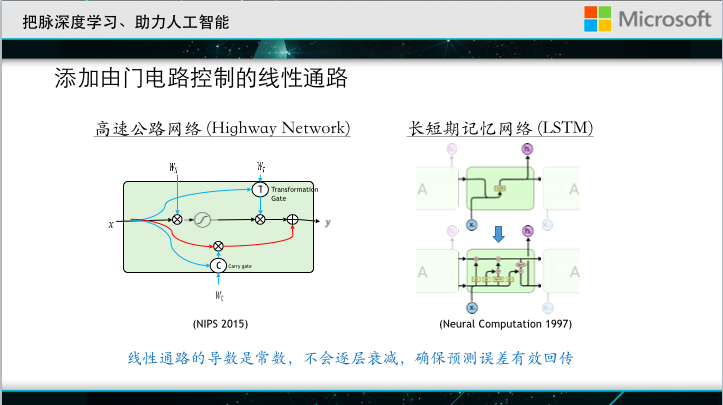
When we pass back, the linear path can pass the prediction error to the final parameter effectively, without the problem of strong gradient reduction. However, the gate circuits used in these two jobs may sometimes pass through, sometimes they will break, or they will bring some losses. Our colleagues from the Institute proposed adding a direct linear path between different levels of the neural network, without any restrictions, and it is always possible. After such a transformation, the effect of solving the gradient reduction problem is better, and it can allow We easily trained tens of thousands of floors of the network, of which 152 layers of residual network participated in last year's competition, and won the championship of five projects, has won the attention of the world.
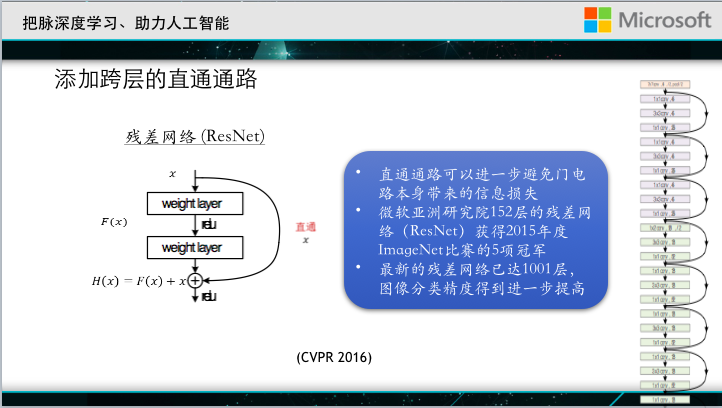
Let's take a look at how deep the 152-storey network is.
In fact, not only will it cause deep trouble, the Internet is also a big problem. This data set is a commonly used mathematical pole in the field of web search. It contains more than 1 billion web pages and the size of the word list is about 10 million. If a neural network is designed based on such data, because the output layer is as large as the vocabulary, the input layer is also as large as the vocabulary, the network size is very considerable, the number of its parameters will exceed 20 billion, and the amount of storage will exceed 200G. This is because the network cannot be plugged into the GPU's memory. Even if it can be stuffed in, it takes a long time to train such a large network. A rough calculation tells us that training with mainstream GPUs takes about 180 years.

C) Use "two-dimensional mapping technology" to reduce the scale of the model
This year our research team proposes new technologies called parametric dimension compression that can effectively solve the problem of oversized vocabularies. Because the vocabulary determines the number of output nodes and the number of input nodes, the core of our work is to present a two-dimensional vector representation of the vocabulary.

Each word is not represented by a node, but represented by two nodes. Different words share nodes. If you use a two-dimensional table to describe all the terms, the original 10,000 words need only 200 elements. The two-dimensional vocabulary structure greatly solves the memory space, but in the end how to generate these two-dimensional vocabulary?
Which words are to share nodes and which words do not need to share nodes. In fact, this is an optimal bipartite graph matching problem. We can solve bipartite graph matching cyclically to obtain a reasonable two-dimensional vocabulary. Correspondingly, we have also improved the traditional neural network and proposed a two-dimensional recurrent neural network.

This network has greatly reduced the memory requirements for network storage. Like the network with 20 billion parameters that I mentioned just now, with this technology, the storage capacity has been reduced by three orders of magnitude, and the amount of operations has been reduced by four orders of magnitude. This is not the most Amazingly, the accuracy has also been improved after we have used two-dimensional shared tables. This is mainly because traditional neural network input nodes are independent of each other, but we did not make such an assumption and we used the optimal bipartite graph. The matching finds the semantic similarity between words and thus improves the accuracy of the network.
IV) How to improve cloud computing and parallel computing
Everyone imagines that if there is really a very large network, there is a lot of data to run. It takes a machine or two hundred years to complete the training. Then you have to use multiple machines for parallel training. The simplest paradigm in parallel training is synchronous parallelism.
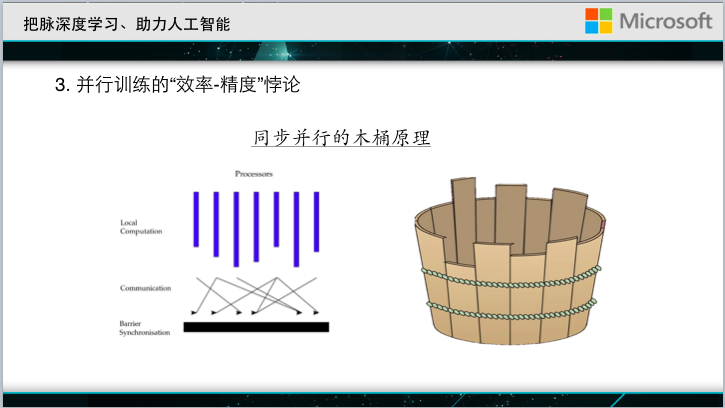
For example, each machine performs a local operation, and then the machines synchronize each other with what they learned. However, the speed of the hundreds of machines may vary greatly. In order to make synchronous updates, the one hundred machines need to wait for each other. The efficiency of the final calculation is determined by the slowest machine.

As a result, the use of 100 machines may be due to waiting for each other, eventually achieving only a three-to-five-fold speed-up, which is not worth the candle. In order to solve this problem, recent scholars have begun to study asynchronous parallelism.

It is that the machines do not wait for each other. This speeds up, but there is a problem of so-called delayed communication. That is, when a machine gets a model update based on the current model and wants to push it back to the global model, the global model is likely to have been updated several times by other machines, causing its push updates to become obsolete and obsolete. The addition of updates to the global model may lead to unexpected results. Some scholars have done analysis, this delay, or lead to slower convergence of learning, and ultimately affect the speedup.
To solve this problem, we need to figure out what impact this outdated update will have. In fact, the difference between this old update and the new update can be described by Taylor's expansion. The traditional asynchronous parallelism is equivalent to only using Taylor's zero-order terms. Then, can we use more high-order terms? Items to compensate for this delay? If all the high-order terms are used, the communication delay can be completely eliminated, but its computational complexity will also increase, so there is a balance problem. We have made a simple attempt to retain more first-order terms on the basis of zero-order terms. However, even with this simple operation, we need to calculate the second derivative of the original loss function (the so-called Hessian array), whose complexity is quite high and may not be worth the loss. Our contribution lies in the proof of an important theorem. When the loss function has the form of a log-likelihood, this second-order derivative can be transformed into an unbiased estimate using a simple transformation of the first derivative. The cross-entropy loss function commonly used in neural networks is a form of log-likelihood, so our technique can be well applied to deep neural networks.
Finally, regarding Microsoft's open source platform
I mentioned in front of a lot of Microsoft's cutting-edge technology in deep learning, these technologies will be gradually shared with the industry through our open source project. One of the open source projects is CNTK, Microsoft Deep Learning Toolkit, and another called DMTK, Microsoft Distributed Machine Learning Toolkit. I hope that my colleagues interested in this area can try out our toolkit and hope to have a driving effect on your research.

Finally, let us discuss our future research directions. We hope to create an artificial intelligence that can automatically create artificial intelligence. Although there are many successful examples of artificial intelligence today, most rely on artificially written programs. In recent years, scholars have been pondering over whether there is any possibility of artificially controlling the process of deep learning. Instead, the machine itself will optimize itself. For example, DeepMind sent a paper this year, which is called learning to learn by gradient descent by gradient descent, which is to replace the artificially-defined gradient descent method with a recurrent neural network. For another example, the dual communication game we mentioned earlier is the machine itself collecting and generating training data. Still others use machine learning methods to automatically tune depth parameters of neural networks, such as learning rate. With the development of these studies, we can imagine that one day machine learning tools can automatically search for data, select data, process data for given tasks, and automatically generate model optimization methods based on the goals you give, automatically adjusting hyperparameters. , Automatically deploy the training to multiple machines for distributed training. If there is such a day, it will be a liberation of all machine learning users. We do not need giants who master black technology, everyone can enjoy Machine learning technology brings everyone the bonus! Let the seemingly sophisticated and sophisticated machine learning technology truly fly into the homes of ordinary people!
Motion control sensor is an original part that converts the change of non-electricity (such as speed, pressure) into electric quantity. According to the converted non-electricity, it can be divided into pressure sensor, speed sensor, temperature sensor, etc. It is a measurement, control instrument and Parts and accessories of equipment.
Remote Control Motion Sensor,Photocell And Motion Sensor,Homeseer Motion Sensor,Lutron Motion Sensor Caseta
Changchun Guangxing Sensing Technology Co.LTD , https://www.gx-encoder.com