1, first come to a conclusion
1. If you want to increase the number of maps, set mapred.map.tasks to a larger value.
2. If you want to reduce the number of maps, set mapred.min.split.size to a larger value.
3. If there are many small files in the input and you still want to reduce the number of maps, you need to use the small file merge as a large file and then use criterion 2.
2. Principle and analysis process
Input Split: Before performing map calculation, mapreduce calculates input splits based on input files. Each input split is input for one map task, input split storage. Not the data itself, but an array of slice lengths and a location where the data is recorded.
Hadoop 2.x default block size is 128MB, Hadoop 1.x default block size is 64MB, you can set dfs.block.size in hdfs-site.xml, pay attention to the unit is byte.
The slice size range can be set in mapred-site.xml, mapred.min.split.size mapred.max.split.size, minSplitSize size defaults to 1B, and maxSplitSize size defaults to Long.MAX_VALUE = 9223372036854775807
So how big is the shard?
minSize=max{minSplitSize, mapred.min.split.size}
maxSize=mapred.max.split.size
splitSize=max{minSize,min{maxSize,blockSize}}
Let's take a look at the source code

So when we don't set the scope of the fragment, the fragment size is determined by the block size, which is the same size. For example, uploading a 258MB file to HDFS, assuming that the block size is 128MB, then it will be divided into three block blocks, corresponding to three splits, so three map tasks will eventually be generated. I found another problem. The file size in the third block is only 2MB, and its block size is 128MB. How much space does it actually occupy the Linux file system?
The answer is the actual file size, not the size of a block.
1. Before adding new files to hdfs, hadoop occupies 464 MB of space on Linux:

2. Add a file with a size of 2673375 bytes (about 2.5 MB) to hdfs:
2673375 derby.jar
3. At this point, hadoop occupies 467 MB of space on Linux - adding an actual file size (2.5 MB) instead of a block size (128 MB):

4. Use hadoop dfs -stat to view file information:

It is very clear here: The file size of the file is 2673375 bytes, but its block size is 128 MB.
5. View the file information through the NameNode web console:
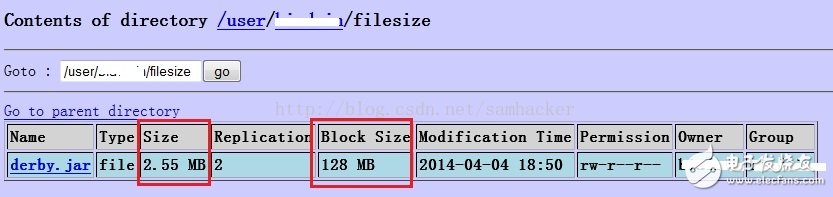
The result is the same: The file size is 2673375 bytes, but its block size is 128 MB.
6, but use 'hadoop fsck' to view the file information, see some different content - '1 (avg.block size 2673375 B)':
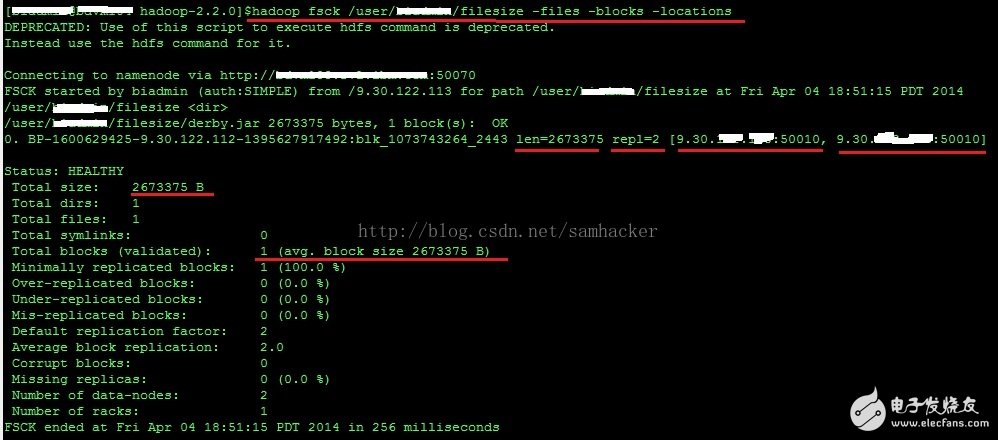
It is worth noting that there is a '1 (avg.block size 2673375 B)' in the result. The 'block size' here does not refer to the usual block size (Block Size) - the latter is a concept of metadata, instead it reflects the file size of the file.
The last question is: If hdfs takes up the disk space of the Linux file system according to the actual file size, is this "block size" necessary?
In fact, the block size is still necessary. An obvious effect is that when the file grows through the append operation, you can determine the time when the file is split by the block size.
supplement:The size of a split is determined by the three values ​​of goalSize, minSize, and blockSize. The logic of computeSplitSize is to select the smallest one from the two values ​​of goalSize and blockSize (for example, generally do not set the map number, then blockSize is the block size of the current file, and goalSize is the file size divided by the number of maps set by the user. If not set, the default is 1).
Hadooop provides a parameter mapred.map.tasks that sets the number of maps. We can control the number of maps by this parameter. But setting the number of maps in this way is not always effective. The reason is that mapred.map.tasks is just a reference value for hadoop, and the final number of maps depends on other factors.
For the convenience of introduction, let's look at a few nouns:
Block_size : The file block size of hdfs, the default is 64M, which can be set by the parameter dfs.block.size
Total_size : the size of the input file as a whole
Input_file_num : the number of input files
(1) The default number of maps
If no settings are made, the default number of maps is related to blcok_size.
Default_num = total_size / block_size;
(2) expected size
The number of maps expected by the programmer can be set by the parameter mapred.map.tasks, but this number will only take effect when it is greater than default_num.
Goal_num = mapred.map.tasks;
(3) Set the processed file size
The file size handled by each task can be set by mapred.min.split.size, but this size will only take effect when it is larger than block_size.
Split_size = max(mapred.min.split.size, block_size);
Split_num = total_size / split_size;
(4) Calculated map number
Compute_map_num = min(split_num, max(default_num, goal_num))
In addition to these configurations, mapreduce also follows some principles. The data processed by each mapreuce cannot span files, that is, min_map_num ">= input_file_num. Therefore, the final number of maps should be:
Final_map_num = max(compute_map_num, input_file_num)
After the above analysis, when setting the number of maps, you can simply summarize the following points:(1) If you want to increase the number of maps, set mapred.map.tasks to a larger value.
(2) If you want to reduce the number of maps, set mapred.min.split.size to a larger value.
(3) If there are many small files in the input and you still want to reduce the number of maps, you need to use the small file merge as a large file and then use criterion 2.
High Current Terminal Blocks,Panel Terminal Block,Feed Through Terminal Block,Heavy Power Terminal Block
Sichuan Xinlian electronic science and technology Company , https://www.sztmlchs.com